Finding similar documents with Word2Vec and WMD¶
Word Mover's Distance is a promising new tool in machine learning that allows us to submit a query and return the most relevant documents. For example, in a blog post OpenTable use WMD on restaurant reviews. Using this approach, they are able to mine different aspects of the reviews. In part 2 of this tutorial, we show how you can use Gensim's WmdSimilarity to do something similar to what OpenTable did. In part 1 shows how you can compute the WMD distance between two documents using wmdistance. Part 1 is optional if you want use WmdSimilarity, but is also useful in it's own merit.
First, however, we go through the basics of what WMD is.
Word Mover's Distance basics¶
WMD is a method that allows us to assess the "distance" between two documents in a meaningful way, even when they have no words in common. It uses word2vec [4] vector embeddings of words. It been shown to outperform many of the state-of-the-art methods in k-nearest neighbors classification [3].
WMD is illustrated below for two very similar sentences (illustration taken from Vlad Niculae's blog). The sentences have no words in common, but by matching the relevant words, WMD is able to accurately measure the (dis)similarity between the two sentences. The method also uses the bag-of-words representation of the documents (simply put, the word's frequencies in the documents), noted as $d$ in the figure below. The intution behind the method is that we find the minimum "traveling distance" between documents, in other words the most efficient way to "move" the distribution of document 1 to the distribution of document 2.
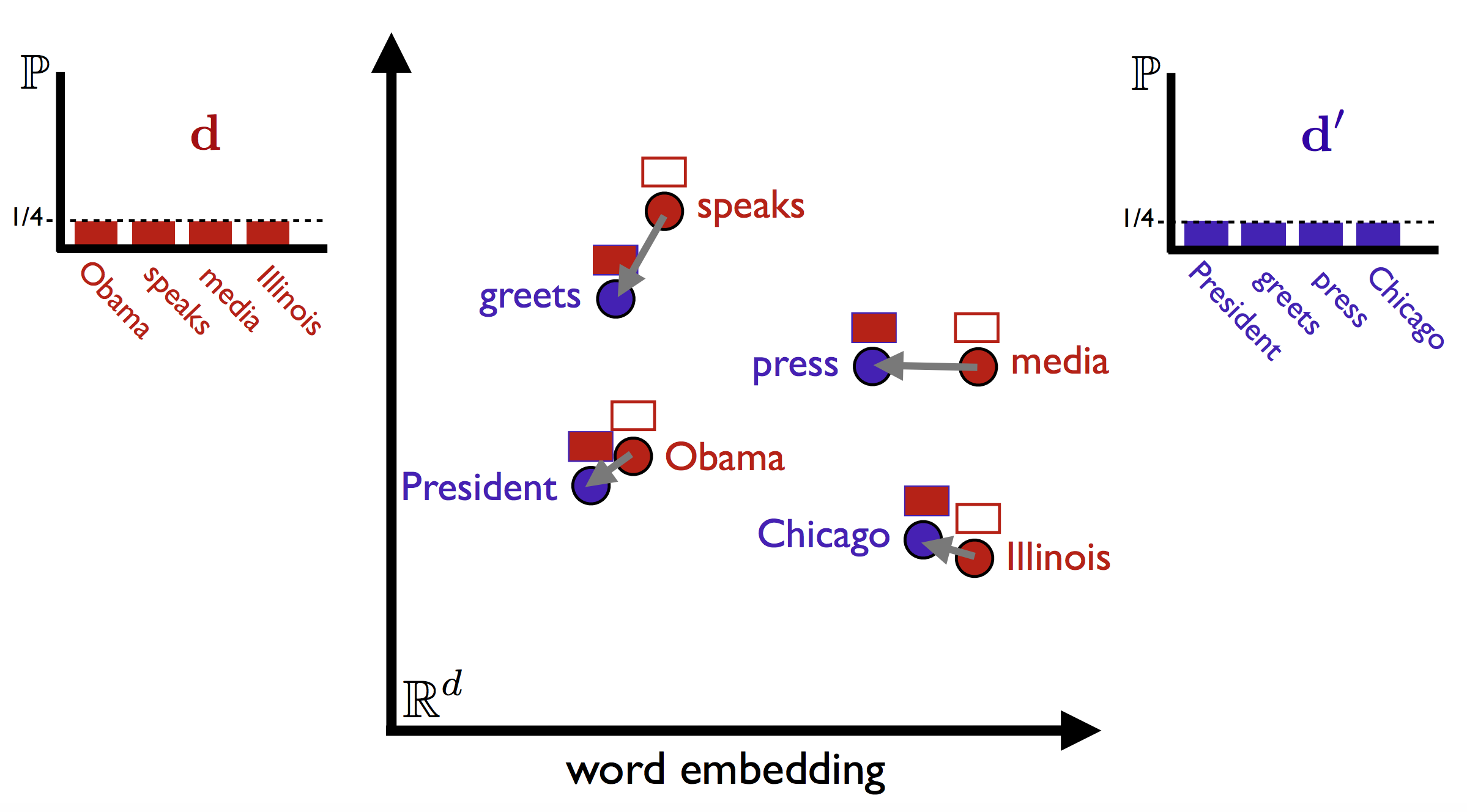
This method was introduced in the article "From Word Embeddings To Document Distances" by Matt Kusner et al. (link to PDF). It is inspired by the "Earth Mover's Distance", and employs a solver of the "transportation problem".
In this tutorial, we will learn how to use Gensim's WMD functionality, which consists of the wmdistance method for distance computation, and the WmdSimilarity class for corpus based similarity queries.
Note:
If you use this software, please consider citing [1], [2] and [3].
Running this notebook¶
You can download this iPython Notebook, and run it on your own computer, provided you have installed Gensim, PyEMD, NLTK, and downloaded the necessary data.
The notebook was run on an Ubuntu machine with an Intel core i7-4770 CPU 3.40GHz (8 cores) and 32 GB memory. Running the entire notebook on this machine takes about 3 minutes.
Part 1: Computing the Word Mover's Distance¶
To use WMD, we need some word embeddings first of all. You could train a word2vec (see tutorial here) model on some corpus, but we will start by downloading some pre-trained word2vec embeddings. Download the GoogleNews-vectors-negative300.bin.gz embeddings here (warning: 1.5 GB, file is not needed for part 2). Training your own embeddings can be beneficial, but to simplify this tutorial, we will be using pre-trained embeddings at first.
Let's take some sentences to compute the distance between.
from time import time
start_nb = time()
# Initialize logging.
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s')
sentence_obama = 'Obama speaks to the media in Illinois'
sentence_president = 'The president greets the press in Chicago'
sentence_obama = sentence_obama.lower().split()
sentence_president = sentence_president.lower().split()
These sentences have very similar content, and as such the WMD should be low. Before we compute the WMD, we want to remove stopwords ("the", "to", etc.), as these do not contribute a lot to the information in the sentences.
# Import and download stopwords from NLTK.
from nltk.corpus import stopwords
from nltk import download
download('stopwords') # Download stopwords list.
# Remove stopwords.
stop_words = stopwords.words('english')
sentence_obama = [w for w in sentence_obama if w not in stop_words]
sentence_president = [w for w in sentence_president if w not in stop_words]
Now, as mentioned earlier, we will be using some downloaded pre-trained embeddings. We load these into a Gensim Word2Vec model class. Note that the embeddings we have chosen here require a lot of memory.
start = time()
import os
from gensim.models import Word2Vec
if not os.path.exists('/data/w2v_googlenews/GoogleNews-vectors-negative300.bin.gz'):
raise ValueError("SKIP: You need to download the google news model")
model = Word2Vec.load_word2vec_format('/data/w2v_googlenews/GoogleNews-vectors-negative300.bin.gz', binary=True)
print('Cell took %.2f seconds to run.' % (time() - start))
So let's compute WMD using the wmdistance method.
distance = model.wmdistance(sentence_obama, sentence_president)
print 'distance = %.4f' % distance
Let's try the same thing with two completely unrelated sentences. Notice that the distance is larger.
sentence_orange = 'Oranges are my favorite fruit'
sentence_orange = sentence_orange.lower().split()
sentence_orange = [w for w in sentence_orange if w not in stop_words]
distance = model.wmdistance(sentence_obama, sentence_orange)
print 'distance = %.4f' % distance
Normalizing word2vec vectors¶
When using the wmdistance method, it is beneficial to normalize the word2vec vectors first, so they all have equal length. To do this, simply call model.init_sims(replace=True) and Gensim will take care of that for you.
Usually, one measures the distance between two word2vec vectors using the cosine distance (see cosine similarity), which measures the angle between vectors. WMD, on the other hand, uses the Euclidean distance. The Euclidean distance between two vectors might be large because their lengths differ, but the cosine distance is small because the angle between them is small; we can mitigate some of this by normalizing the vectors.
Note that normalizing the vectors can take some time, especially if you have a large vocabulary and/or large vectors.
Usage is illustrated in the example below. It just so happens that the vectors we have downloaded are already normalized, so it won't do any difference in this case.
# Normalizing word2vec vectors.
start = time()
model.init_sims(replace=True) # Normalizes the vectors in the word2vec class.
distance = model.wmdistance(sentence_obama, sentence_president) # Compute WMD as normal.
print 'Cell took %.2f seconds to run.' %(time() - start)
Part 2: Similarity queries using WmdSimilarity¶
You can use WMD to get the most similar documents to a query, using the WmdSimilarity class. Its interface is similar to what is described in the Similarity Queries Gensim tutorial.
Important note:
WMD is a measure of distance. The similarities in
WmdSimilarityare simply the negative distance. Be careful not to confuse distances and similarities. Two similar documents will have a high similarity score and a small distance; two very different documents will have low similarity score, and a large distance.
Yelp data¶
Let's try similarity queries using some real world data. For that we'll be using Yelp reviews, available at http://www.yelp.com/dataset_challenge. Specifically, we will be using reviews of a single restaurant, namely the Mon Ami Gabi.
To get the Yelp data, you need to register by name and email address. The data is 775 MB.
This time around, we are going to train the Word2Vec embeddings on the data ourselves. One restaurant is not enough to train Word2Vec properly, so we use 6 restaurants for that, but only run queries against one of them. In addition to the Mon Ami Gabi, mentioned above, we will be using:
The restaurants we chose were those with the highest number of reviews in the Yelp dataset. Incidentally, they all are on the Las Vegas Boulevard. The corpus we trained Word2Vec on has 18957 documents (reviews), and the corpus we used for WmdSimilarity has 4137 documents.
Below a JSON file with Yelp reviews is read line by line, the text is extracted, tokenized, and stopwords and punctuation are removed.
# Pre-processing a document.
from nltk import word_tokenize
download('punkt') # Download data for tokenizer.
def preprocess(doc):
doc = doc.lower() # Lower the text.
doc = word_tokenize(doc) # Split into words.
doc = [w for w in doc if not w in stop_words] # Remove stopwords.
doc = [w for w in doc if w.isalpha()] # Remove numbers and punctuation.
return doc
start = time()
import json
# Business IDs of the restaurants.
ids = ['4bEjOyTaDG24SY5TxsaUNQ', '2e2e7WgqU1BnpxmQL5jbfw', 'zt1TpTuJ6y9n551sw9TaEg',
'Xhg93cMdemu5pAMkDoEdtQ', 'sIyHTizqAiGu12XMLX3N3g', 'YNQgak-ZLtYJQxlDwN-qIg']
w2v_corpus = [] # Documents to train word2vec on (all 6 restaurants).
wmd_corpus = [] # Documents to run queries against (only one restaurant).
documents = [] # wmd_corpus, with no pre-processing (so we can see the original documents).
with open('/data/yelp_academic_dataset_review.json') as data_file:
for line in data_file:
json_line = json.loads(line)
if json_line['business_id'] not in ids:
# Not one of the 6 restaurants.
continue
# Pre-process document.
text = json_line['text'] # Extract text from JSON object.
text = preprocess(text)
# Add to corpus for training Word2Vec.
w2v_corpus.append(text)
if json_line['business_id'] == ids[0]:
# Add to corpus for similarity queries.
wmd_corpus.append(text)
documents.append(json_line['text'])
print 'Cell took %.2f seconds to run.' %(time() - start)
Below is a plot with a histogram of document lengths and includes the average document length as well. Note that these are the pre-processed documents, meaning stopwords are removed, punctuation is removed, etc. Document lengths have a high impact on the running time of WMD, so when comparing running times with this experiment, the number of documents in query corpus (about 4000) and the length of the documents (about 62 words on average) should be taken into account.
from matplotlib import pyplot as plt
%matplotlib inline
# Document lengths.
lens = [len(doc) for doc in wmd_corpus]
# Plot.
plt.rc('figure', figsize=(8,6))
plt.rc('font', size=14)
plt.rc('lines', linewidth=2)
plt.rc('axes', color_cycle=('#377eb8','#e41a1c','#4daf4a',
'#984ea3','#ff7f00','#ffff33'))
# Histogram.
plt.hist(lens, bins=20)
plt.hold(True)
# Average length.
avg_len = sum(lens) / float(len(lens))
plt.axvline(avg_len, color='#e41a1c')
plt.hold(False)
plt.title('Histogram of document lengths.')
plt.xlabel('Length')
plt.text(100, 800, 'mean = %.2f' % avg_len)
plt.show()

Now we want to initialize the similarity class with a corpus and a word2vec model (which provides the embeddings and the wmdistance method itself).
# Train Word2Vec on all the restaurants.
model = Word2Vec(w2v_corpus, workers=3, size=100)
# Initialize WmdSimilarity.
from gensim.similarities import WmdSimilarity
num_best = 10
instance = WmdSimilarity(wmd_corpus, model, num_best=10)
The num_best parameter decides how many results the queries return. Now let's try making a query. The output is a list of indeces and similarities of documents in the corpus, sorted by similarity.
Note that the output format is slightly different when num_best is None (i.e. not assigned). In this case, you get an array of similarities, corresponding to each of the documents in the corpus.
The query below is taken directly from one of the reviews in the corpus. Let's see if there are other reviews that are similar to this one.
start = time()
sent = 'Very good, you should seat outdoor.'
query = preprocess(sent)
sims = instance[query] # A query is simply a "look-up" in the similarity class.
print 'Cell took %.2f seconds to run.' %(time() - start)
The query and the most similar documents, together with the similarities, are printed below. We see that the retrieved documents are discussing the same thing as the query, although using different words. The query talks about getting a seat "outdoor", while the results talk about sitting "outside", and one of them says the restaurant has a "nice view".
# Print the query and the retrieved documents, together with their similarities.
print 'Query:'
print sent
for i in range(num_best):
print
print 'sim = %.4f' % sims[i][1]
print documents[sims[i][0]]
Let's try a different query, also taken directly from one of the reviews in the corpus.
start = time()
sent = 'I felt that the prices were extremely reasonable for the Strip'
query = preprocess(sent)
sims = instance[query] # A query is simply a "look-up" in the similarity class.
print 'Query:'
print sent
for i in range(num_best):
print
print 'sim = %.4f' % sims[i][1]
print documents[sims[i][0]]
print '\nCell took %.2f seconds to run.' %(time() - start)
This time around, the results are more straight forward; the retrieved documents basically contain the same words as the query.
WmdSimilarity normalizes the word embeddings by default (using init_sims(), as explained before), but you can overwrite this behaviour by calling WmdSimilarity with normalize_w2v_and_replace=False.
print 'Notebook took %.2f seconds to run.' %(time() - start_nb)
References¶
- Ofir Pele and Michael Werman, A linear time histogram metric for improved SIFT matching, 2008.
- Ofir Pele and Michael Werman, Fast and robust earth mover's distances, 2009.
- Matt Kusner et al. From Embeddings To Document Distances, 2015.
- Thomas Mikolov et al. Efficient Estimation of Word Representations in Vector Space, 2013.